How do you know that pattern-matching alone can ever be sufficient in itself? What if passing a Turing Test on a significant scale requires more than that?Originally Posted by John J. Xenakis
- Join Date
- Sep 2001
- Posts
- 9,412
How do you know that pattern-matching alone can ever be sufficient in itself? What if passing a Turing Test on a significant scale requires more than that?
Actually, it doesn't show anything like that, unless we assume that human interaction is entirely governed by fundamentally rigid rules that always interact in the same ways. One of the ironies of the success of chess playing software is that it's demonstrated how little chess actually reveals about intelligence and consciousness.
Again, only if human interaction is basically like chess. What if it's actually a chaotic system like weather? If so, brute force will never be sufficient in the foreseeable future.In 1970, the best chess-playing program was quite weak. Today, the
best chess-playing program uses roughly the same minimax algorithm,
but is world champion class. The improvement from "weak" to "world
championship class" came about strictly from increasing computer
speed. Similarly, the ability to pass the Turing Test will come with
increased computer speed.
Yes, Moore formulated his statement as a prediction of technological capability, then proceeded to demonstrate its practical applicability in his business. It was a sort of self-fulfilling prophecy. Again, that does not imply that such a observation applies to any area outside of chip fabrication. Moore himself has said that he never intend any such generalization.
Of course there are other vendors that followed Intel's development curve; the vendors that did not are no longer in the chip business. Again, that says everything about Intel and little about any underlying "law".
All of the technologies listed were narrowly focused on similar goals, such as ballistics and data collation, hence there was a clear effort to improve performance from one generation to the next. The problem is in ascribing "predictive" power to such an effort.
Yes, there are many phenomena in the modern world that fit well with exponential trendlines. That still says very little about the ability to use such models for predictive purposes. Repeat after me: "correlation does not imply causation."
Did you read the transcripts? They're barely better than the ELIZA program I was running on my little TRS-80 twenty years ago. As I said, the problem is not that the Turing Test is an insurmountable obstacle; the problem is that hardly anybody is putting any effort into addressing the Turing Test. Even those who refer to themselves as professional AI researchers view the Turing Test with embarrassment if not disdain. The matter of AI has simply been redefined to mean something more achievable in the short term.
No, I did in fact mean "Deep Blue". It was a general-purpose computer, but its minimax algorithm was tuned to beat Kasparov's particular playing style. Note above that I said "built for specialized purposes"; e.g. "ASCI Q" was built to perform nuclear weapons simulations. It could be used to run the Turing Test, but I doubt LANL or the DoE would authorize that. 8)
Shows by analogy?? Analogies are useful for illuminating hard concepts, but they are of limited help in solving hard problems. Chess is amenable to brute-force because the basic algorithms used by grandmasters have been well-understood for over a hundred years. I can easily go buy a book that will reliably guide me to improve my chess game. There is no comparable book that will reliably teach me to improve my intelligence (snake-oil salesmen aside.)
The reason is that issues of intelligence, creativity, etc. are still quite poorly understood. This is not to say that they will never be amenable to brute-force approaches; after all, we are capable of learning, and (all metaphysical distractions aside) such learning clearly takes place by some sort of material interaction between atoms and quarks and fields and whatever, so eventually some machine could theoretically be capable of emulating the same process. However, we've barely even reached the level of beginning to ask the right questions, let alone start moving toward any answers.
Dear Rick,
I'm totally confused about what you're saying.
Are you saying that the fact that computer power has been doubling
every 18 months is a business decision, not a technological
imperative?
Are you saying that Intel could have made a different business
decision and computer power could have doubled every 12 months
instead of every 18 months?
Please clarify what you're saying, about why computer power has been
doubling every 18 months since the 1950s.
Sincerely,
John
John J. Xenakis
E-mail: john@GenerationalDynamics.com
Web site: http://www.GenerationalDynamics.com
Dear Hopeful Cynic 68,
OK, then here's where we have a big problem. I've explained how
super-intelligent computers can create and invent things, I've
described the algorithm, and I've given several examples, and I could
give dozens more if I had to.
All you can do is say "What if you're wrong," but you have nothing --
you give no reasons, you have no support, you can't even provide one
simple example. You have nothing.
So if you're satisfied with the case you've made, then I wish you
luck. But as for me, you've given me absolutely no reason to agree
with you.
So what? Just because you have a mathematical model of why the sky
is blue doesn't mean you have it right. What if something is going
on at the sub-atomic level that no one even knows about or can
measure? Then your mathematical model would be completely wrong.
So your explanation of why the sky is blue is useless, according to
the methodology you've been using to criticize me. The fact is that
you can't explain anything at all if you follow your own rules.
The rules don't have to be rigid, but the rules for human interaction
are indeed available in numerous books -- books on grammar and style,
books on protocol, military manuals, books on how to play music, and
so forth. Those rules can be easily programmed in software on a
computer several orders of magnitudes more powerful than today's
computers.
There are people who act chaotically, and they're mostly in
nuthouses. If what you're saying is true, then a person from another
country and culture could never come to America, learn the language
and succeed.
You know, I don't really believe that you believe what you're saying.
If you did, then you'd at least have an example of some kind. I think
you're playing devil's advocate.
Sincerely,
John
John J. Xenakis
E-mail: john@GenerationalDynamics.com
Web site: http://www.GenerationalDynamics.com
Yes, that is precisely what I am saying. Intel made a business decision, to design a production process that ramped up yields and chip densities at a certain rate. This rate was determined by the market, i.e. how quickly the market could absorb Intel's R&D costs.
Yes, absolutely. It would have been the wrong business decision, because in all likelihood the market would not have been willing to amortize Intel's chip foundry investments over such a short period. In addition, the costs per chip would have been much worse due to the lower yield. The 18-month period is what Intel requires to "dial in" its production processes, so as to produce a chip yield high enough to allow its chips to be sold at a profit. That profit is partially determined by the rate at which it cannibalizes its own sales of slower chips.
The technique of photolithography has not changed much in the last 30 years. The fundamental physical model is this: you can keep reducing feature sizes as far as you want, until you start approaching the single-atom levels. Until you get there, the business model is this: you can put as many features as you want into a given square centimeter, and the total cost doesn't change. The marginal cost of manufacturing a silicon IC is approximately equal to (cost of silicon wafer x # of chips per wafer.) The cost of the silicon wafer is fairly constant, so the only "knob" to turn is to increase the # of chips per wafer (i.e. the yield.) An Intel chip line is only profitable when the yield is close to 99%. It takes some time to bring the yield up when a feature size reduction is introduced, but once the yield is back up, it doesn't cost Intel any more to put a million transistors into a mm^2 than to put a thousand. The yield curve is the business driver.
It's late for me here, and I have a feeling that I didn't formulate that all too clearly; but you can probably find a much better description than that in any number of business or science texts. Again, to emphasize, the growth in performance of Intel's chips is a deliberate business decision on Intel's part. The 18-month cycle is entirely their choice. They could have done it differently, in which case "Moore's Law" would have a different coefficient that would appear in retrospect to have an equally obvious "technological imperative".
On the other hand, if they had moved more slowly, IBM or perhaps Texas Instruments would now be the world leader, so business competition is a clear factor here. Intel can and does introduce new chip iterations according to market pressures, not science breakthroughs. Eventually, market pressures will bring about the end of Moore's Law, by which I mean photolithography will no longer have sufficient economic returns to continue pursuing it.
Meanwhile, Intel (along with IBM and others) are investigating completely different chip technologies (such as molecular computing and quantum computing.) It is quite likely that the yield curve for such technologies will not be on an 18-month schedule. It could be much longer; I suspect it will actually be much shorter. Clearly technological progress will continue; but the 18-month-doubling is just an accident of history, not a remotely reliable indicator of future trends past the next few years.
Could be. But the models fit the observed evidence to date. That's the difference, there are no observed examples of any form of artificial invention. We have no models that account for the processes occuring in the brain during creative thought. It's not just a question of wrong models, we don't have any models that match up with anything we can measure.
Sure we can, because it fits the observed evidence, and the predictions made by the model are borne out by experiment. That's the difference. The predictions made by the various models of human thought have yet to match the evidence to any significant degree.
Then your mathematical model would be completely wrong.
So your explanation of why the sky is blue is useless, according to
the methodology you've been using to criticize me. The fact is that
you can't explain anything at all if you follow your own rules.
Those 'rules' are not general or complete. They apply in specific situations, and in practice are never[ followed rigidly. They always vary with context and interaction, and never repeated in exactly the same way. Humans are very good at such 'soft' cues, but we don't know how we do it.
The rules don't have to be rigid, but the rules for human interaction
are indeed available in numerous books -- books on grammar and style,
books on protocol, military manuals, books on how to play music, and
so forth. Those rules can be easily programmed in software on a
computer several orders of magnitudes more powerful than today's
computers.
That's not what chaos means in this context. I'm talking about 'chaotic systems', phenomena that display what students of the field call 'sensitive dependence on initial conditions'. Such systems are by nature unpredictable, even when you know the starting rules, no matter how much processing power you have, because the required processing power increases exponentially with the passage of time.
There are people who act chaotically, and they're mostly in
nuthouses. If what you're saying is true, then a person from another
country and culture could never come to America, learn the language
and succeed.
That's not originality, that's pattern matching. They are two different things.
No, that's not how things are invented! That's the point you keep missing.
The aspects of the creative process that we don't understand involve perceiving that list, and understanding what constitutes a useful choice. It's the old "I could have thought of that." problem. The mark of a creative thinker is that s/he sees something nobody has perceived before, and usually it's something obvious, after it's perceived.
What we don't understand about the creative process, to this day, is how that perception works, and how the creative thought perceives part of the list of possibilities that was invisible previously. It wasn't that the possibility didn't exist, it was that somehow, nobody could perceive that part of the list until then.
In fact, there is more than one kind of creativity. Some individuals seem to be gifted with the ability to perceive previously unrecognized possibilities in physics and in terms of 'physical law'. Often (but not always) they have no ability whatever to perceive how the new possibilities they've discovered can be used practically.
Is the creativity of the business genius the same process as the creativity of the physics genius? We don't know.
In fact, we understand one aspect of the creative process far better than the other: the process of skeptical analysis and testing we 'get'. Computers are very useful in that aspect of the process, and could be make better by straightforward brute-force techniques of testing.
But we don't even know how to begin programming a computer to perceive something we can't define.
Yes, that might be what the brain is doing. Now if we understood how the brain does that, we'd be well on our way to understanding how it physically works. But that still wouldn't necessarily shed any light on creative thinking. To do that, we'd have to ask how the first human to think of a chair did so.
Actually, that's only (at best) part of the process of invention, and we don't know how to combine the bits in new ways.
In fact, there's another element to the creative process that we can observe and describe, but that which we don't really comprehend: the ability to perceive bits of information that hitherto were there, but never recognized.
Those are very good questions, and given our current level of understanding, we can not provide any meaninful answers. Anybody's guess is as good as anyone else's.
Dear Rick,
You know, this is such a completely different view of things that
it's completely irreconcilable with anything I can say. You and I
have fundamentally different views of both technology and economics.
I'll give a couple of reasons why I don't agree with you, but the
difference is so fundamental that these reasons only scratch the
surface:
(*) I've been surrounded by technologists all my life, and I've been
a technologist all my life. On my journalist side, I've written
hundreds of articles about technology. I've never heard any
engineer, any manager, any analyst, any customer, any educator,
anybody -- that they're purposely slowing down product development in
the long range in order to meet a predefined marketing curve for
technology development. In fact, I think you're the first person
I've ever heard it from at all.
(*) I guess you're saying that all the different chip vendors have
colluded with one another to stay on the same technology curve. Chip
development is a very competitive field, and there's no way that
could happen. Even if there were some sort of such agreement, then
one of the vendors would "cheat" a little and push the curve up from
18-month doubling to 17-month doubling, then someone else would
"cheat" and bring it to 16-months, etc. In other words, if 12 months
were possible, it would have happened.
(*) You're right that production costs play an integral part in
product development, but you can't beat the technology curve in the
long run by spending more money. You might come out with a product
six months early by spending a lot more money, but you couldn't
maintain a 12-month doubling rate that way. All you could do is
maintain the same 18-month doubling rate but at much higher costs.
(*) Incidentally, the same thing is true if you decided to go slower.
You could come out with products later than competitors, and you
could save money and come out with lower cost products. Some vendors
do that. But they still double their power every 18 months like
everyone else.
By the way, an interesting historical note is that in Moore's
original paper in 1965, he predicted a doubling rate of 12 months.
It turned out be 18 months, I guess because the engineers couldn't
keep up with his business plan.
Sincerely,
John
P.S.: See http://www.intel.com/research/silicon/mooreslaw.htm
John J. Xenakis
E-mail: john@GenerationalDynamics.com
Web site: http://www.GenerationalDynamics.com
Dear Hopeful Cynic 68,
Once again, you can't be sure. You have a model that produces a blue
color, but the sky displays different shades of blue at the same
time. In fact, if you look up at the sky on a nice day, I'll bet
you'd see billions of different shades of blue. You have absolutely
no way of showing that your model explains what you're seeing, so
according to your rules you have no way of explaining why the sky is
blue.
That's not true - I've described such a model. And it describes
brain processes just as adequately as your model for describing why
the sky is blue.
That's true, but it supports my contention rather than yours.
In the chess example, the computer has to follow the rigid rules, or
it's making a mistake.
But in interaction rules, there's a lot more flexibility, so even if
the computer doesn't precisely do what some particular human would
do, it's still OK. For example, if a computer mispronounces a word,
that's OK because humans sometimes mispronounce words.
The super-intelligent computers will have a job to do -- whatever job
is set for them at any given time. If they don't do it exactly like
one human, then it doesn't matter, as long as the job gets done.
The remark about nuthouses was a joke, but I guess it wasn't very
funny.
As you know, a chaotic system is one in which a small variation in
initial conditions can produce wildly varying behavior. The example
that the public is most familiar with is the "butterfly effect,"
where the tiny variation in atmospheric conditions caused by a
butterfly flapping its wings in China is enough to affect a change in
weather in the US in an unpredictable manner.
However, human beings are clearly not chaotic systems. Take the
behavior of a man getting up and going to work in the morning. If
it's sunny, he gets up and goes to work. If it's raining, he gets up
and goes to work. If his car breaks down, he borrows his wife's car
and goes to work.
In other words, human beings are highly stable systems, which is why
their behavior can be programmed. It doesn't matter if the computer
does everything in precisely the same way as some particular human
being, as long as the goal gets accomplished (get up and go to work).
Once again, if you really believe that, then give me a simple
example.
We understand generally how a brain recognizes a chair. We don't
have to understand the brain's process any more deeply than that, as
long as we can program a computer to do what we want -- recognize a
chair. If it matches the method used by the brain of some particular
human then fine, but if not it doesn't matter as long as it gets the
job done.
Same answer as before: as long as we can program a computer to do
it in one way -- and we can -- then it really doesn't matter if it's
the same as some particular human being does it, as long as it gets
the job done.
That's just one more part of the algorithm that has to be programmed.
Sincerely,
John
John J. Xenakis
E-mail: john@GenerationalDynamics.com
Web site: http://www.GenerationalDynamics.com
Actually, it accounts for it quite well. The shadings are partly determined by the different frequencies being refracted in different ways by the atmosphere, and partly by the specific color-receptivity of the eye and nervous system.
WHEN did you describe such a model? I've gone through the whole thread and I haven't found it.
That's not true - I've described such a model. And it describes
brain processes just as adequately as your model for describing why
the sky is blue.
??? There isn't anything to prove, that's the definition of the creative process as far we we know it! Every creative thought is like that.
Once again, if you really believe that, then give me a simple
example.
But we don't know how to program that! I never said it was impossible, I said we don't know how to program a computer to do it, at any level of processing power.
.
That's just one more part of the algorithm that has to be programmed.
Actually, I think we agree on most points; we are just using different words to describe the same thing. It's a rather pointless discussion any way, because we have no way of determining what might have happened if Intel had done things differently. At any rate, the 18-month doubling is an observed fact. I was simply explaining why I think it is quite possible that the observed exponential growth only applies to a fairly narrow window (of technology and business environment.) It is quite possible that a future technology or business/legal environment will follow a very different path.
You're being a little disingenuous here. Of course business and marketing plays a huge role in when and how new products are introduced. We engineers may chafe at it, but it's always the "suits" who have the final say. As we both agree, the reason why Intel has not introduced products at a faster-than-18-month cycle is because to do so would not be maximally profitable. Remember, Intel is mostly in competition with itself: sales of new chip lines come primarily at the expense of sales of older (more profitable) chip lines, since it has only one real (rarely profitable) competitor in AMD.
One additional, very important consideration in all this: semiconductors, automation and "high tech" in general owe much of their commercial success to the massive support of the military-industrial complex. Without the Pentagon, it's quite possible that the chip industry would never have taken off. So, in attempting to discern what the future of the high-tech industry will look like, it is helpful to determine the areas where the Pentagon is currently focusing. As I said, AI is definitely not one of those areas; efforts to make computers act more like humans have basically stagnated for the last thirty years. However, efforts to make humans more like computers continue apace. I can furnish many examples if you are interested.
Dear Hopeful Cynic 68,
Well, you're right; I've only given a brief outline, with most of the
algorithm still in my head. So below I'm giving a more detailed version
of the algorithm as I see it.
This represents about a couple of hour's work for a job that really
should take weeks. That means that it's going to contain holes.
Therefore, I'd like to propose that this be approached more
constructively. Instead of pointing out a million holes, which we both
know you can do, how about if the discussion focused on how to improve
the algorithm, rather than just what's wrong with it.
In the following description, I'll use two abbreviations:
IC = intelligent computer
KB = knowledge bit
We'll be describing the IC algorithm, which consists of algorithms for
creating and combining KBs to create new KBs.
What will the IC look like?
We're going to be talking about intelligent computers "doing things,"
so we want to give an example of what they might look like.
As an example, here's a picture I posted earlier in this topic:
This robot is available today and it's not, of course, an intelligent
computer. The robot is controlled by wireless communications from
the laptop computer you see in the upper left hand corner, where a
human being types in commands. In the 2020s, these kinds of robots
will be autonomous intelligent computers, able to set goals, make
decisions, and talk to people.
As we'll see when I discuss the algorithm, the first versions of ICs
will not be able to do everything, because the computers will not be
sufficiently powerful. Instead, there'll be ICs that are "experts" at
certain things. For example, an expert plumber IC wouldn't be
configured like the one shown above. Instead, it would have an arm
whose "hand" is an adjustable wrench. This same arm might have an "eye"
on the end of it, so that it can see behind walls. Try to get a human
plumber to do that!!!
Other special purpose robots might do household chores (including
solving jigsaw puzzles), clean up environmental waste sites, provide
language translation, act as 24 hour a day home care nurses, or act as
soldiers in war where people get killed.
As the ICs become increasingly powerful, it'll be possible at some point
for a single computer to "do it all."
Jigsaw puzzle analogy
The IC algorithm requires putting together little bits of knowledge to
get bigger pieces of knowledge. There's a partial analogy to putting
together jigsaw puzzle pieces, so let's look at how to solve a jigsaw
puzzle.
If you have a puzzle of say 1000 pieces or so, then you look for
clues that might make it easier to fit pieces together. You look for
pieces of similar color, and you look for edge and corner pieces.
Those are techniques for reducing the complexity of the problem.
There's another method you could use to solve this puzzle: You could
try to match every piece to every other piece trying to find matches.
In fact, this is what you'd have to do in the case of one of
those "Deep Blue Sea" jigsaw puzzles where all the pieces have the
same solid color blue.
But in either case, the computer has a big advantage over the human
being, and this is worth noting.
The computer can "look" at all 1000 pieces, and store their images
into its temporary memory. It can then "solve" the problem entirely
in its memory, and assemble the final puzzle quickly afterwards.
Humans do not have the ability to quickly learn the shapes of 1000
jigsaw puzzle pieces, and then match them up in their minds. Human
beings cannot quickly learn 1000 facts of any sort. Things like
learning multiplication tables, or lists of vocabulary words, or
lists of historical dates are very painful and time consuming for most
humans, but are very easy for computers.
This is a very big advantage for computers in many ways. Consider
learning a foreign language. Once one computer has learned it, then
any other computer can simply load the same software. Human beings
are different. A human takes years to learn a foreign language, and
then the knowledge can't be transferred to another human being.
This is one reason why computers will shoot ahead of human beings,
once they reach a certain "tipping point" of intelligence. This
ability to temporarily "memorize" last lists of things quickly and
then used the list for problem solving "in one's head" can be used
not only for jigsaw puzzles but also for warfare, research and all
kinds of problem solving.
Knowledge Bits (KBs)
I'm going to describe how an intelligent computer learns, by
combining bits of knowledge the way you combine jigsaw puzzle pieces.
a "knowledge bit" or KB is such a bit of knowledge. It will be
possible to combine KBs analogously to how jigsaw puzzle pieces are
combined, with the following capability: When a bunch of KBs are
combined in a meaningful way. then result is a new KB which can be
further combined with others.
Attributes of KBs
Returning to the jigsaw analogy, we know that a puzzle piece has
certain attributes -- things like colors, edge shapes, and so forth.
Human beings especially use colors as clues to find adjacent puzzle
pieces.
Well, what are the attributes of KBs?
At first I thought that a KB would have no attributes whatsoever.
After all, a human baby's brain starts out as a "clean slate," able
to learn anything. Assigning attributes would only limit the ability
of the intelligent computer to learn unfamiliar things.
So attributes like color are not part of any KB. Instead, an
attribute is assigned by having a separate KB.
So, if we talk about a "brown chair," then we're actually talking
about two (or more) separate KBs, one that says we have a chair, and
another that says, "the chair is brown."
So, although KBs don't have attributes, there are nonetheless
different kinds of KBs. Some KBs identify physical objects (like
chairs), and others describe attributes.
Still others are rules. For example, a child may see several brown
chairs made of wood, and conclude that "All brown chairs are made of
wood." This is an example of a rule KB that an intelligent computer
might "learn," until the day that it encounters a brown chair made of
plastic. This illustrates how rules might be learned and later
refined.
How many different types of KBs are there? By referencing a
thesaurus, I've come up a list of several hundred categories of
English words, and each of those could arguably correspond to a type
of KB. I'll describe this below.
"Noticing" physical objects
The intelligent computer algorithm is going to have thousands of
modules, and I can't make any attempt to do more than describe a few
sample chunks of the algorithm.
An IC learns about physical objects by "noticing" them.
Noticing things is often called "attention to detail" in human
beings. This is sometimes described in gender terms, that women have
a greater attention to detail than men. For example, I could spend
an hour talking to someone, and if you asked me later I probably
couldn't tell you what color clothing he was wearing, but almost
every woman I know would be able to do so.
It also relates to circumstances. A doctor examining a patient might
notice something that a layman wouldn't notice. I wouldn't even
notice an ordinary bird chirp in the distance, but a bird watcher
would not only notice it, but would immediately classify it as to the
type of bird.
When an IC notices something, then it can add to its set of KBs. For
example, if there's a room full of chairs, the IC might or might not
notice them. If it notices them, then it can add to its KB base a
bunch of rules about what colors chairs can have, what chairs cam be
made of, and so forth.
There will have to be a number of "noticing" algorithms. In early
versions, the IC will only notice things that it's told to notice.
Later, it will develop rule KBs for noticing things. Such rules are
usually in the form of "If something looks odd, then notice it."
For example, if the IC is looking for red chairs, it might notice a
bunch of chairs in a room as a group, ignore all the non-red chairs,
but then notice each red chair individually.
In humans, every object that's noticed seems to get a name in some
way. It might be a person's name (that person introduced himself,
and his name is Joe), or it might be a description (the chair that I
sat on last night). If the IC notices an object, then the object
itself is a KB, but there also has to be one or more KBs that
identify the object in some way.
Obtaining sensual data
Quite possibly the greatest advantage that humans have over computers
today is the ability to identify things by sight.
Natural voice recognition is coming along pretty well, and natural
language processing is advancing, but computer vision is still pretty
primitive.
Early versions of the IC will probably not depend on computer vision
on more than a limited basis. Most of the "learning" processes will
be done through natural language processing. For example, the Oxford
English Dictionary (OED) is available on disk, and software can be
written so that the IC can read the OED disk and "learn" from it by
creating the necessary collection of KBs.
Once that's done, the IC will be able to "read" simple books, such as
children's or high school level books. As time goes on, the IC will
develop a reading skill just as a human learns to read, and
eventually will be able to read complex texts. Once that point is
reached, the IC will be able to learn almost anything very quickly.
I don't believe that it will take very long before this is possible.
I think that by 2015 a computer will be able to process text and
learn from it.
The IC will also have to be able to learn from hearing spoken words
and from seeing things. These are essentially pattern matching
problems, and will be possible with more powerful computers that can
perform massively parallel pattern matches in real time.
Algorithms will be developed to turn "hearing" and "vision" into KBs.
Development of these algorithms will require help from experts in
the fields of voice recognition and computer vision. These
algorithms will be tied into other "noticing" and rule-building
algorithms previously summarized.
As for smell and taste, I'm not aware that any meaningful advances
have been made for those senses, and I doubt that they would be
required for an IC anyway. Still, it's possible that something useful
on smell and taste will come out of the current research on
biotechnology.
Example: Learning "Jane is Joe's sister"
How does the computer learn the Knowledge Bit: "Jane is Joe's
sister"?
This is an example of how one KB is created from other KBs. The
following description shows some of the steps involved in learning
the above fact, and it illustrates how KBs fit together to form other
KBs.
(*) What is a person?
One of the first thing that a baby learns is the concept of "person."
Mom and dad are persons, as are friends and parents' friends. Baby
also learns that "I'm a person." However, confusion comes from the
question, "Is Fido a person?"
It won't be so hard for the IC to learn what a person is, since it
will be written into the software at the beginning.
(*) Jane is a person.
At some point, the IC "noticed" a person, and somehow learned that
this person has the name "Jane." There are many ways that the IC
could have learned this -- through being told, or through a more
complex inference. Human beings learn people's names in many ways --
talking to them in person or on the phone, seeing a photo, reading
something they authored, and so forth. The IC will also have
multiple algorithms for learning a person's name.
(*) Joe is a person
(*) Frank is a person
(*) Helen is a person
(*) Married people
You learn what "married people" are in childhood. You see people in
pairs -- your parents, neighbors, aunts and uncles. Later, you learn
refinements: boy/girl friends, divorced couples. This same
information will be taught to the IC.
(*) Frank and Helen are married people
(*) Frank and Helen are Jane's parents
These last two KBs could have been learned in numerous ways, as in the
case of learning someone's names.
(*) Frank and Helen are Joe's parents
(*) Jane is female
The IC might learn this in many ways, depending on its KBs and its
capabilities. The name "Jane" is a pretty good indication, but there
may also have been written text that refers to Jane as "she." With
additional capabilities, the IC could identify a female by clothing
and appearance, or by voice.
(*) Rule: If X is female, and Y is a person, and X and Y& have the
same parents, then X is Y's sister.
The IC could have learned this from scanning a dictionary and
learning the definition of "sister."
(*) Therefore, Jane is Joe's sister.
This is the final step, where all the above KBs are combined into a
new KB, "Jane is Joe's sister."
I'm not going to attempt to describe this algorithm, except to point
out that a lot of work has been done on this sort of thing. "Expert
systems," for example, are designed specifically to take sets of
facts and rules and derive new conclusions. A person with expertise
in expert systems would probably be the best person to implement this
part of the IC algorithm.
Self-awareness, motivations, goals and sub-goals
In one of Schwartzenegger's Terminator movies, a bunch of
computers get linked together, suddenly develop "self-awareness," and
decide to kill off all the human beings.
What does self-awareness mean? I've previously said that I don't
know what self-awareness is, but if you can tell me what it means,
then I'll tell you how to implement it in the IC software.
However, upon further reflection, I think I do know what
self-awareness means. It means that the IC has a self-preservation
algorithm. In the extreme case, it acts like the Terminator
computers: "I have to preserve myself; a human being could turn off
the power; therefore I have to kill all humans."
At any rate, my point is that you implement things like
self-awareness and motivations by implement goals. There are
transient goals -- "Your job today is to fix the plumbing" -- and
there are permanent goals, such as might be implement according to
the example of Maslow's Hierarchy of Needs:
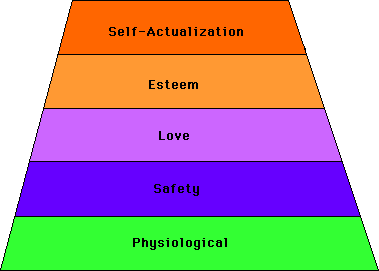
I don't know what the analog to "love" would be for an intelligent
computer, but at least it has to be thought through.
How does an IC achieve a goal? Once again, we can turn to expertise
developed in expert systems. These systems have developed the
technology of taking sets of rules, taking a goal as input, and
finding a way from the rules to seek out the appropriate sub-goals,
and finally arrive at the desired goal.
By the way, it's because of this stuff about goal-setting and
self-awareness that I believe it's important for people to start
thinking about all this. If the goal algorithm is implemented
incorrectly, then the ICs may decide, autonomously, to start killing
humans. This project will take thousands of man-years to develop
anyway, and it's important to understand these kinds of implications as
early as possible.
Goal: Find all "sisters" in the room.
Just to give one more example, let's work through an example of
reaching a goal. Suppose that an IC has as a goal or sub-goal the
job of figuring all the people in the room who are somebody's sister.
Here's an outline of the steps:
(*) Looking up the KB that defines "sister," the IC immediately
excludes all chairs, tables, and other non-persons in the room. It
also excludes all male persons. That leaves only the female persons
in the room.
(*) For each female person in the room, set the sub-goal of
determining whether that person is a sister. If there are 100 female
persons in the room, the IC now has 100 sub-goals to achieve.
Now, given a female person, how does the IC achieve the sub-goal of
determining whethet that female person is a sister?
The IC may already "know"; that is, there may already be an IC that
says that that person is someone's sister.
Otherwise, it has to go through all its KBs, to search for ways that
it's previously learned that someone was a sister. For example, the
IC might search for all KBs that indicate that some person is a
sister. The IC can then go back and figure out where the KB came
from, and then go through the same steps with the new person, if
possible.
(*) If the IC can talk, it can ask the female person if she's
someone's sister.
(*) If the IC has online access to personnel records or other records
about the person, it can check the online records to see if that
person is someone's sister.
(*) If the IC is a sleeping baby, then the IC can look for a nearby
parent or guardian, and ask that person if the baby is someone's
sister.
(*) If the IC has a suitable KB, then it may select one person in the
room and ask that person whether other people in the room are
some people's sisters. That way, the IC can save time, asking one
person about several other people.
Kinds of KBs
I previously said that I wanted a way of describing different types
of KBs. In order to do this, I went to a thesaurus, Roget's 21st
century Thesaurus, edited by Barbara Ann Kipfer, PhD., Head
lexicographer, Dell Publishing, 1993.
This book contains a "concept index" at the end which breaks 17,000
words down into 837 groups. The 837 groups appear in ten major
categories broken into several dozen sub-categories.
Here's a list of the ten major categories, along with the
sub-categories for each category:
(*) Actions: class of, cognitive, communicative, general, motion,
physical.
(*) Causes: Abstract, physical
(*) Fields of human activity: Agriculture, the arts, communications,
education, entertainment, family, government and politics, health,
legal, military, monetary and financial affairs, professions,
recreation, religious, sex and reproduction, social interactions
(*) Life forms: Beings, beings - animal, general characeristics,
humans, plants
(*) Objects: Articles - physical, atmosphere, building - furnishings
- possessions, clothing, food and drink, machines, matter -
conditions of, matter - divisions of, matter - qualities of, tools,
transportation
(*) The Planet: Geography, habitats, natural resources, weather
(*) Qualities: Abstract, comparative, physical
(*) Senses: Aspects of perception, auditory, olfactory, tactile,
tasting, visual
(*) States: Abstract, cognitive, comparative, of being, of change, of
need or achievement, physical, spatial
(*) Weights and measures: Mathematics, quantifiers, time, wholeness
or division
Just to give you a better idea of how this works, notice that the
"Causes" category contains two sub-categories, abstract and physical.
Here's a list of the groups that appear in the "Causes" category,
sub-category "abstract": affect, event that causes another, state of
causation, to be, to change, to change abstractly, to change an event,
to change cognitively, to change number of quantity, to change or
affect an event, to change state of being, to continue, to diminish,
to function, to happen, to have, to improve, to increase quantity, to
injure, to reduce quantity.
From the above groups, here's a list of the words that appear in the
"To reduce quantity" group: abbreviate, abridge, abstract, alleviate,
commute, compress, condense, contract, curtail, cut, cut back, deduct,
deflate, detract, digest, discount, downsize, lessen, lower, minimize,
modify, narrow, pure, prune, reduce, shorten, slash, summarize, take,
trim, truncate, whittle
Here's a list of the groups that appear in the "Causes" category,
sub-category "physical": to break, to burn, to change physically, to
create, to destroy, to grow, to make dirty, to ake hot or cold, to
make wet.
From the above groups, here's a list of the words that appear in the
"To burn" group: arson, blaze, burn, char, conflagration, fire,
flame, flare, glow, ignite, inflame, kindle, lick, light, porch,
scorch, sear, smolder
I hope the above examples give you a flavor of how the 17,000 words
are broken down into groups, sub-categories, and categories.
It's quite possible that the IC algorithm will require considering
each of the 17,000 words, or at least each of the 837 groups.
It may also be necessary to consider all relationships between pairs
of words, but this list can be pared down substantially, and all the
information can be obtained from the OED, if properly processed.
Now, this is a huge amount of work, and may require thousands of
man-years of effort. But the point is that it's a fairly
well-defined job that can be completed within a few years.
Summary
The above is a pretty reasonable algorithm, and it wouldn't surprise
me if someone was implementing something like it already.
Early versions of this algorithm could be working in 10-15 years and
producing useful results, perhaps in solving math problems or
something like that. In the early 2020s time frame, special purpose
robots should be available to do things like fix plumbing or act as
24x7 nursing. By 2030 or so, fully functional super-intelligent
autonomous robots will be available.
At some point around 2030, there'll be a bend in the technology
curve, so the graph will look like this (on a logarithmic scale):
That bend is where The Singularity occurs, when super-intelligent
computers take off on their own path, able to improve themselves. By
2050 or so, super-intelligent computers will be as much more
intelligent than human beings as human beings are more intelligent
than cats and dogs.
This is a fascinating software project, and I'd love to be involved
in developing it, though I don't think I will be. On the other hand,
my son Jason, who's a freshman at Georgia Tech majoring in
biotechnology, and who has absolutely no fear of anything including
the fourth turning, the clash of civilizations, or the Singularity,
tells me that he's looking forward to participating heavily in the
development of the first super-intelligent computer. I wish him well.
Sincerely,
John
John J. Xenakis
E-mail: john@GenerationalDynamics.com
Web site: http://www.GenerationalDynamics.com
Dear Hopeful Cynic 68,
Well, you're right; I've only given a brief outline, with most of the
algorithm still in my head. So below I'm giving a more detailed version
of the algorithm as I see it.
This represents about a couple of hour's work for a job that really
should take weeks. That means that it's going to contain holes.
Therefore, I'd like to propose that this be approached more
constructively. Instead of pointing out a million holes, which we both
know you can do, how about if the discussion focused on how to improve
the algorithm, rather than just what's wrong with it.
In the following description, I'll use two abbreviations:
IC = intelligent computer
KB = knowledge bit
We'll be describing the IC algorithm, which consists of algorithms for
creating and combining KBs to create new KBs.
What will the IC look like?
We're going to be talking about intelligent computers "doing things,"
so we want to give an example of what they might look like.
As an example, here's a picture I posted earlier in this topic:
This robot is available today and it's not, of course, an intelligent
computer. The robot is controlled by wireless communications from
the laptop computer you see in the upper left hand corner, where a
human being types in commands. In the 2020s, these kinds of robots
will be autonomous intelligent computers, able to set goals, make
decisions, and talk to people.
As we'll see when I discuss the algorithm, the first versions of ICs
will not be able to do everything, because the computers will not be
sufficiently powerful. Instead, there'll be ICs that are "experts" at
certain things. For example, an expert plumber IC wouldn't be
configured like the one shown above. Instead, it would have an arm
whose "hand" is an adjustable wrench. This same arm might have an "eye"
on the end of it, so that it can see behind walls. Try to get a human
plumber to do that!!!
Other special purpose robots might do household chores (including
solving jigsaw puzzles), clean up environmental waste sites, provide
language translation, act as 24 hour a day home care nurses, or act as
soldiers in war where people get killed.
As the ICs become increasingly powerful, it'll be possible at some point
for a single computer to "do it all."
Jigsaw puzzle analogy
The IC algorithm requires putting together little bits of knowledge to
get bigger pieces of knowledge. There's a partial analogy to putting
together jigsaw puzzle pieces, so let's look at how to solve a jigsaw
puzzle.
If you have a puzzle of say 1000 pieces or so, then you look for
clues that might make it easier to fit pieces together. You look for
pieces of similar color, and you look for edge and corner pieces.
Those are techniques for reducing the complexity of the problem.
There's another method you could use to solve this puzzle: You could
try to match every piece to every other piece trying to find matches.
In fact, this is what you'd have to do in the case of one of
those "Deep Blue Sea" jigsaw puzzles where all the pieces have the
same solid color blue.
But in either case, the computer has a big advantage over the human
being, and this is worth noting.
The computer can "look" at all 1000 pieces, and store their images
into its temporary memory. It can then "solve" the problem entirely
in its memory, and assemble the final puzzle quickly afterwards.
Humans do not have the ability to quickly learn the shapes of 1000
jigsaw puzzle pieces, and then match them up in their minds. Human
beings cannot quickly learn 1000 facts of any sort. Things like
learning multiplication tables, or lists of vocabulary words, or
lists of historical dates are very painful and time consuming for most
humans, but are very easy for computers.
This is a very big advantage for computers in many ways. Consider
learning a foreign language. Once one computer has learned it, then
any other computer can simply load the same software. Human beings
are different. A human takes years to learn a foreign language, and
then the knowledge can't be transferred to another human being.
This is one reason why computers will shoot ahead of human beings,
once they reach a certain "tipping point" of intelligence. This
ability to temporarily "memorize" last lists of things quickly and
then used the list for problem solving "in one's head" can be used
not only for jigsaw puzzles but also for warfare, research and all
kinds of problem solving.
Knowledge Bits (KBs)
I'm going to describe how an intelligent computer learns, by
combining bits of knowledge the way you combine jigsaw puzzle pieces.
a "knowledge bit" or KB is such a bit of knowledge. It will be
possible to combine KBs analogously to how jigsaw puzzle pieces are
combined, with the following capability: When a bunch of KBs are
combined in a meaningful way. then result is a new KB which can be
further combined with others.
Attributes of KBs
Returning to the jigsaw analogy, we know that a puzzle piece has
certain attributes -- things like colors, edge shapes, and so forth.
Human beings especially use colors as clues to find adjacent puzzle
pieces.
Well, what are the attributes of KBs?
At first I thought that a KB would have no attributes whatsoever.
After all, a human baby's brain starts out as a "clean slate," able
to learn anything. Assigning attributes would only limit the ability
of the intelligent computer to learn unfamiliar things.
So attributes like color are not part of any KB. Instead, an
attribute is assigned by having a separate KB.
So, if we talk about a "brown chair," then we're actually talking
about two (or more) separate KBs, one that says we have a chair, and
another that says, "the chair is brown."
So, although KBs don't have attributes, there are nonetheless
different kinds of KBs. Some KBs identify physical objects (like
chairs), and others describe attributes.
Still others are rules. For example, a child may see several brown
chairs made of wood, and conclude that "All brown chairs are made of
wood." This is an example of a rule KB that an intelligent computer
might "learn," until the day that it encounters a brown chair made of
plastic. This illustrates how rules might be learned and later
refined.
How many different types of KBs are there? By referencing a
thesaurus, I've come up a list of several hundred categories of
English words, and each of those could arguably correspond to a type
of KB. I'll describe this below.
"Noticing" physical objects
The intelligent computer algorithm is going to have thousands of
modules, and I can't make any attempt to do more than describe a few
sample chunks of the algorithm.
An IC learns about physical objects by "noticing" them.
Noticing things is often called "attention to detail" in human
beings. This is sometimes described in gender terms, that women have
a greater attention to detail than men. For example, I could spend
an hour talking to someone, and if you asked me later I probably
couldn't tell you what color clothing he was wearing, but almost
every woman I know would be able to do so.
It also relates to circumstances. A doctor examining a patient might
notice something that a layman wouldn't notice. I wouldn't even
notice an ordinary bird chirp in the distance, but a bird watcher
would not only notice it, but would immediately classify it as to the
type of bird.
When an IC notices something, then it can add to its set of KBs. For
example, if there's a room full of chairs, the IC might or might not
notice them. If it notices them, then it can add to its KB base a
bunch of rules about what colors chairs can have, what chairs cam be
made of, and so forth.
There will have to be a number of "noticing" algorithms. In early
versions, the IC will only notice things that it's told to notice.
Later, it will develop rule KBs for noticing things. Such rules are
usually in the form of "If something looks odd, then notice it."
For example, if the IC is looking for red chairs, it might notice a
bunch of chairs in a room as a group, ignore all the non-red chairs,
but then notice each red chair individually.
In humans, every object that's noticed seems to get a name in some
way. It might be a person's name (that person introduced himself,
and his name is Joe), or it might be a description (the chair that I
sat on last night). If the IC notices an object, then the object
itself is a KB, but there also has to be one or more KBs that
identify the object in some way.
Obtaining sensual data
Quite possibly the greatest advantage that humans have over computers
today is the ability to identify things by sight.
Natural voice recognition is coming along pretty well, and natural
language processing is advancing, but computer vision is still pretty
primitive.
Early versions of the IC will probably not depend on computer vision
on more than a limited basis. Most of the "learning" processes will
be done through natural language processing. For example, the Oxford
English Dictionary (OED) is available on disk, and software can be
written so that the IC can read the OED disk and "learn" from it by
creating the necessary collection of KBs.
Once that's done, the IC will be able to "read" simple books, such as
children's or high school level books. As time goes on, the IC will
develop a reading skill just as a human learns to read, and
eventually will be able to read complex texts. Once that point is
reached, the IC will be able to learn almost anything very quickly.
I don't believe that it will take very long before this is possible.
I think that by 2015 a computer will be able to process text and
learn from it.
The IC will also have to be able to learn from hearing spoken words
and from seeing things. These are essentially pattern matching
problems, and will be possible with more powerful computers that can
perform massively parallel pattern matches in real time.
Algorithms will be developed to turn "hearing" and "vision" into KBs.
Development of these algorithms will require help from experts in
the fields of voice recognition and computer vision. These
algorithms will be tied into other "noticing" and rule-building
algorithms previously summarized.
As for smell and taste, I'm not aware that any meaningful advances
have been made for those senses, and I doubt that they would be
required for an IC anyway. Still, it's possible that something useful
on smell and taste will come out of the current research on
biotechnology.
Example: Learning "Jane is Joe's sister"
How does the computer learn the Knowledge Bit: "Jane is Joe's
sister"?
This is an example of how one KB is created from other KBs. The
following description shows some of the steps involved in learning
the above fact, and it illustrates how KBs fit together to form other
KBs.
(*) What is a person?
One of the first thing that a baby learns is the concept of "person."
Mom and dad are persons, as are friends and parents' friends. Baby
also learns that "I'm a person." However, confusion comes from the
question, "Is Fido a person?"
It won't be so hard for the IC to learn what a person is, since it
will be written into the software at the beginning.
(*) Jane is a person.
At some point, the IC "noticed" a person, and somehow learned that
this person has the name "Jane." There are many ways that the IC
could have learned this -- through being told, or through a more
complex inference. Human beings learn people's names in many ways --
talking to them in person or on the phone, seeing a photo, reading
something they authored, and so forth. The IC will also have
multiple algorithms for learning a person's name.
(*) Joe is a person
(*) Frank is a person
(*) Helen is a person
(*) Married people
You learn what "married people" are in childhood. You see people in
pairs -- your parents, neighbors, aunts and uncles. Later, you learn
refinements: boy/girl friends, divorced couples. This same
information will be taught to the IC.
(*) Frank and Helen are married people
(*) Frank and Helen are Jane's parents
These last two KBs could have been learned in numerous ways, as in the
case of learning someone's names.
(*) Frank and Helen are Joe's parents
(*) Jane is female
The IC might learn this in many ways, depending on its KBs and its
capabilities. The name "Jane" is a pretty good indication, but there
may also have been written text that refers to Jane as "she." With
additional capabilities, the IC could identify a female by clothing
and appearance, or by voice.
(*) Rule: If X is female, and Y is a person, and X and Y& have the
same parents, then X is Y's sister.
The IC could have learned this from scanning a dictionary and
learning the definition of "sister."
(*) Therefore, Jane is Joe's sister.
This is the final step, where all the above KBs are combined into a
new KB, "Jane is Joe's sister."
I'm not going to attempt to describe this algorithm, except to point
out that a lot of work has been done on this sort of thing. "Expert
systems," for example, are designed specifically to take sets of
facts and rules and derive new conclusions. A person with expertise
in expert systems would probably be the best person to implement this
part of the IC algorithm.
Self-awareness, motivations, goals and sub-goals
In one of Schwartzenegger's Terminator movies, a bunch of
computers get linked together, suddenly develop "self-awareness," and
decide to kill off all the human beings.
What does self-awareness mean? I've previously said that I don't
know what self-awareness is, but if you can tell me what it means,
then I'll tell you how to implement it in the IC software.
However, upon further reflection, I think I do know what
self-awareness means. It means that the IC has a self-preservation
algorithm. In the extreme case, it acts like the Terminator
computers: "I have to preserve myself; a human being could turn off
the power; therefore I have to kill all humans."
At any rate, my point is that you implement things like
self-awareness and motivations by implement goals. There are
transient goals -- "Your job today is to fix the plumbing" -- and
there are permanent goals, such as might be implement according to
the example of Maslow's Hierarchy of Needs:
I don't know what the analog to "love" would be for an intelligent
computer, but at least it has to be thought through.
How does an IC achieve a goal? Once again, we can turn to expertise
developed in expert systems. These systems have developed the
technology of taking sets of rules, taking a goal as input, and
finding a way from the rules to seek out the appropriate sub-goals,
and finally arrive at the desired goal.
By the way, it's because of this stuff about goal-setting and
self-awareness that I believe it's important for people to start
thinking about all this. If the goal algorithm is implemented
incorrectly, then the ICs may decide, autonomously, to start killing
humans. This project will take thousands of man-years to develop
anyway, and it's important to understand these kinds of implications as
early as possible.
Goal: Find all "sisters" in the room.
Just to give one more example, let's work through an example of
reaching a goal. Suppose that an IC has as a goal or sub-goal the
job of figuring all the people in the room who are somebody's sister.
Here's an outline of the steps:
(*) Looking up the KB that defines "sister," the IC immediately
excludes all chairs, tables, and other non-persons in the room. It
also excludes all male persons. That leaves only the female persons
in the room.
(*) For each female person in the room, set the sub-goal of
determining whether that person is a sister. If there are 100 female
persons in the room, the IC now has 100 sub-goals to achieve.
Now, given a female person, how does the IC achieve the sub-goal of
determining whethet that female person is a sister?
The IC may already "know"; that is, there may already be an IC that
says that that person is someone's sister.
Otherwise, it has to go through all its KBs, to search for ways that
it's previously learned that someone was a sister. For example, the
IC might search for all KBs that indicate that some person is a
sister. The IC can then go back and figure out where the KB came
from, and then go through the same steps with the new person, if
possible.
(*) If the IC can talk, it can ask the female person if she's
someone's sister.
(*) If the IC has online access to personnel records or other records
about the person, it can check the online records to see if that
person is someone's sister.
(*) If the IC is a sleeping baby, then the IC can look for a nearby
parent or guardian, and ask that person if the baby is someone's
sister.
(*) If the IC has a suitable KB, then it may select one person in the
room and ask that person whether other people in the room are
some people's sisters. That way, the IC can save time, asking one
person about several other people.
Kinds of KBs
I previously said that I wanted a way of describing different types
of KBs. In order to do this, I went to a thesaurus, Roget's 21st
century Thesaurus, edited by Barbara Ann Kipfer, PhD., Head
lexicographer, Dell Publishing, 1993.
This book contains a "concept index" at the end which breaks 17,000
words down into 837 groups. The 837 groups appear in ten major
categories broken into several dozen sub-categories.
Here's a list of the ten major categories, along with the
sub-categories for each category:
(*) Actions: class of, cognitive, communicative, general, motion,
physical.
(*) Causes: Abstract, physical
(*) Fields of human activity: Agriculture, the arts, communications,
education, entertainment, family, government and politics, health,
legal, military, monetary and financial affairs, professions,
recreation, religious, sex and reproduction, social interactions
(*) Life forms: Beings, beings - animal, general characeristics,
humans, plants
(*) Objects: Articles - physical, atmosphere, building - furnishings
- possessions, clothing, food and drink, machines, matter -
conditions of, matter - divisions of, matter - qualities of, tools,
transportation
(*) The Planet: Geography, habitats, natural resources, weather
(*) Qualities: Abstract, comparative, physical
(*) Senses: Aspects of perception, auditory, olfactory, tactile,
tasting, visual
(*) States: Abstract, cognitive, comparative, of being, of change, of
need or achievement, physical, spatial
(*) Weights and measures: Mathematics, quantifiers, time, wholeness
or division
Just to give you a better idea of how this works, notice that the
"Causes" category contains two sub-categories, abstract and physical.
Here's a list of the groups that appear in the "Causes" category,
sub-category "abstract": affect, event that causes another, state of
causation, to be, to change, to change abstractly, to change an event,
to change cognitively, to change number of quantity, to change or
affect an event, to change state of being, to continue, to diminish,
to function, to happen, to have, to improve, to increase quantity, to
injure, to reduce quantity.
From the above groups, here's a list of the words that appear in the
"To reduce quantity" group: abbreviate, abridge, abstract, alleviate,
commute, compress, condense, contract, curtail, cut, cut back, deduct,
deflate, detract, digest, discount, downsize, lessen, lower, minimize,
modify, narrow, pure, prune, reduce, shorten, slash, summarize, take,
trim, truncate, whittle
Here's a list of the groups that appear in the "Causes" category,
sub-category "physical": to break, to burn, to change physically, to
create, to destroy, to grow, to make dirty, to ake hot or cold, to
make wet.
From the above groups, here's a list of the words that appear in the
"To burn" group: arson, blaze, burn, char, conflagration, fire,
flame, flare, glow, ignite, inflame, kindle, lick, light, porch,
scorch, sear, smolder
I hope the above examples give you a flavor of how the 17,000 words
are broken down into groups, sub-categories, and categories.
It's quite possible that the IC algorithm will require considering
each of the 17,000 words, or at least each of the 837 groups.
It may also be necessary to consider all relationships between pairs
of words, but this list can be pared down substantially, and all the
information can be obtained from the OED, if properly processed.
Now, this is a huge amount of work, and may require thousands of
man-years of effort. But the point is that it's a fairly
well-defined job that can be completed within a few years.
Summary
The above is a pretty reasonable algorithm, and it wouldn't surprise
me if someone was implementing something like it already.
Early versions of this algorithm could be working in 10-15 years and
producing useful results, perhaps in solving math problems or
something like that. In the early 2020s time frame, special purpose
robots should be available to do things like fix plumbing or act as
24x7 nursing. By 2030 or so, fully functional super-intelligent
autonomous robots will be available.
At some point around 2030, there'll be a bend in the technology
curve, so the graph will look like this (on a logarithmic scale):
That bend is where The Singularity occurs, when super-intelligent
computers take off on their own path, able to improve themselves. By
2050 or so, super-intelligent computers will be as much more
intelligent than human beings as human beings are more intelligent
than cats and dogs.
This is a fascinating software project, and I'd love to be involved
in developing it, though I don't think I will be. On the other hand,
my son Jason, who's a freshman at Georgia Tech majoring in
biotechnology, and who has absolutely no fear of anything including
the fourth turning, the clash of civilizations, or the Singularity,
tells me that he's looking forward to participating heavily in the
development of the first super-intelligent computer. I wish him well.
Sincerely,
John
John J. Xenakis
E-mail: john@GenerationalDynamics.com
Web site: http://www.GenerationalDynamics.com
Dear Rick,
Let me try and explain it a different way. What I've been arguing is
that the 18-month doubling period is a technological imperative, and if
a company wanted to change and have its computers double in power every
12 months, they wouldn't be able to do it.
But it's also true in the opposite direction. Suppose a company wanted
its computers to double in power every 24 months. Then look what
they'd have to do. At the end of two years, they'd have to use 6 month
old technology. At the end of four years, they'd have to use 12 month
old technology. Each cycle, they'd get more and more out of date.
After a while, they'd be using such old technology that the supporting
chips and devices would become unavailable.
If a company wanted to get ahead of the curve, even spending a lot more
money, they couldn't. After a year, they'd have to be 6 months ahead
of the technology curve; after two years, they'd have to be a year
ahead; and so forth. You might be able to spend a lot of money and get
6 months ahaed, but you could never get 12 or 18 months ahead.
Sincerely,
John
John J. Xenakis
E-mail: john@GenerationalDynamics.com
Web site: http://www.GenerationalDynamics.com
Dear Rick,
Let me try and explain it a different way. What I've been arguing is
that the 18-month doubling period is a technological imperative, and if
a company wanted to change and have its computers double in power every
12 months, they wouldn't be able to do it.
But it's also true in the opposite direction. Suppose a company wanted
its computers to double in power every 24 months. Then look what
they'd have to do. At the end of two years, they'd have to use 6 month
old technology. At the end of four years, they'd have to use 12 month
old technology. Each cycle, they'd get more and more out of date.
After a while, they'd be using such old technology that the supporting
chips and devices would become unavailable.
If a company wanted to get ahead of the curve, even spending a lot more
money, they couldn't. After a year, they'd have to be 6 months ahead
of the technology curve; after two years, they'd have to be a year
ahead; and so forth. You might be able to spend a lot of money and get
6 months ahaed, but you could never get 12 or 18 months ahead.
Sincerely,
John
John J. Xenakis
E-mail: john@GenerationalDynamics.com
Web site: http://www.GenerationalDynamics.com
I see John's given this a little thought . . . :wink:
Americans have had enough of glitz and roar . . Foreboding has deepened, and spiritual currents have darkened . . .
THE FOURTH TURNING IS AT HAND.
See T4T, p. 253.
I see John's given this a little thought . . . :wink:
Americans have had enough of glitz and roar . . Foreboding has deepened, and spiritual currents have darkened . . .
THE FOURTH TURNING IS AT HAND.
See T4T, p. 253.
Just a little.
John
Just a little.
John
On machine intelligence:
Difficult computational problems are generally categorized according to their parallelizability: that is, how easy is it to split up the computation into individual, independent chunks. The "hardest" problems involve billions of individual computation units that are all tightly dependent on the results of other units. The classic example is finite element analysis, such as used in the simulation of nuclear explosions and weather systems: each simulated particle's behavior is dependent on the behavior of all the "neighboring" particles. Solving problems of this type requires a collection of processors that are very tightly coupled, where the speed of interconnection is more of a bottleneck than the processing power of the individual units. This has some interesting implications.
First, the biggest, baddest supercomputers in the world are required for such problems. Indeed, the very definition of a supercomputer (performance on the LINPACK benchmark) is the ability to address problems involving tightly coupled computations. However, since the interconnections are the limiting factor, the processing units themselves can be simpler, off-the-shelf components. Indeed, we see this in the Top500 rankings. As recently as 1997, specialized vector processors (mostly from Cray) dominated the Top500 rankings, providing over 90% of the world's supercomputing capacity; but since 2001, not a single vector processor appears in the Top500 at all! Instead, over 40% of the Top500 capacity is provided by standard x86 desktop-type chips.
Second, as the expensive interconnect technology enters the mainstream (with the explosive growth of the Internet), we see the cost of supercomputing technology decreasing dramatically, although not quite at the 18-month-halving rate of processors in particular. It is now possible to assemble a supercomputer entirely from off-the-shelf hardware and software, as Virginia Tech has done. In fact, it is possible to build a (temporary) supercomputer for free, using donated computer time and open-source software, as demonstrated here.
How is this relevant to Machine Intelligence? Well, virtually every model of human cognition indicates that it is a supercomputing-class problem, in that the interconnection capability is as significant as the processing capability. The "cycle time" of an individual neuron is on the order of 50-100 ms, yet humans are capable of completing cognitive tasks in 500 ms, i.e. in only 5-10 "neural cycles". This would be the equivalent of a typical desktop CPU completing a task in a few hundredths of a microsecond. Humans can do that, and computers cannot, and clearly this has something to do with the massive number of interconnections between neurons. Of course, we still don't know for sure exactly how the brain works, but in all likelihood, simulating a brain will require supercomputer-level technology.
That is not to say that other computational arrangements are not useful. Some problems requiring immense computing power can easily be broken into completely independent chunks. Such problems are referred to as "trivially parallelizable." The best example is protein folding: to target a drug to a particular cellular (or viral) receptor, a drug company must design a protein with a particular three-dimensional shape. Currently, the only way to do this is to try every possible sequence of proteins. The number of possible sequences is in the quintillions, but each sequence can be computed and tested individually, without consulting the results for any other sequence. Thus, one possible approach to such problems is to distribute individual computational units among thousands or even millions of individual computers. This is known as "distributed computing"; United Devices' GRID.org and Stanford's Folding@home are two real-world examples. (SETI@Home is another example, but its scientific value is more dubious.) The distributed computing approach has the advantage that setup and maintenance are much simpler; both projects just listed use a screensaver program to take advantage of desktop computers' idle cycles. Thus the cost is also much lower, close to zero.
Unfortunately, as discussed, distributed computing is a poor model for John's "Intelligent Computer". However, the process of gathering the "Knowledge Bits" that John described can easily be distributed. In fact, there is a very active project where exactly this approach is being attempted: MIT Media Lab's CommonSense OpenMind. OpenMind currently has over 600,000 "knowledge bits" in its database. The entire CommonSense database can be downloaded for free; combine this with a few thousand off-the-shelf PCs, and you can have an Intelligent Computer of your very own.
Yet such an IC would not even approach the capabilities of a typical 1-year-old child. Why? Well, let's leave aside metaphysical concerns for the moment and look at one example: language acquisition. Language is the most distinctive, and most widely studied, of all human behaviors. Yet we still know so very little about how it is learned. One thing is clear: a child most definitely does not acquire language by assembling a collection of facts, as John implies. When I want to teach my child what a tree is, I don't say "A tree is a perennial woody plant having a main trunk and usually a distinct crown." I don't even say something simpler, like "A tree is something you can climb on. They make nice shade in the summer, and the leaves change colors and fall off when it gets cooler. Trees are made out of wood. Some of them have fruit on them." I just point to a tree and say, "tree." This simple experience, and thousands of more methodical studies, indicate that a child acquires the meaning of a word generally with a single exposure. This could only be possible if the concept of (say) a tree exists in the child's brain before it ever hears the word. In fact, it seems that all human languages share the same ten thousand or so basic concepts, and simply assign different series of sounds to the various internally represented concepts.
Thus, it appears that the human brain is hard-wired for language acquisition and production. Essentially, our brains are highly-tuned, special-purpose computing devices, not general-purpose computers like the typical PC. This has enormous implications for the future development of "intelligent" machines.